Persistence
This section covers a basic overview of how Horta persists neurons, workspaces, samples and preferences.
Asynchronous vs synchronous saving
The final persistence store for Horta is in MongoDB, a document database, whether or not the data being saved is asynchronous or synchronous. Most Horta data is saved synchronously; the purpose of the asynchronous saving is to:
Ease the burden on the annotator to constantly save their workShare annotations in realtime with other annotators or machine algorithms working in the same workspace
Persistence flow
All access to MongoDB is wrapped by a RESTful API, jacs-sync, with a number of endpoints for CRUD operations for TmWorkspace, TmSample, and TmNeuronMetadata. The basic class/component diagram is shown below. When a workspace is first loaded, it relies on NeuronModelAdapter to stream in parallel all the neuron annotations for that workspace into the client app. The following initialization steps are performed with the annotation data:
Concurrent map in NeuronModel is populated:LoadWorkspace/Sample events are fired to notify relevant GUI panels to updateSpatial Filters are initialized with vertices (TmGeoAnnotations) from the neurons for snapping and general neighborhood convenience methods
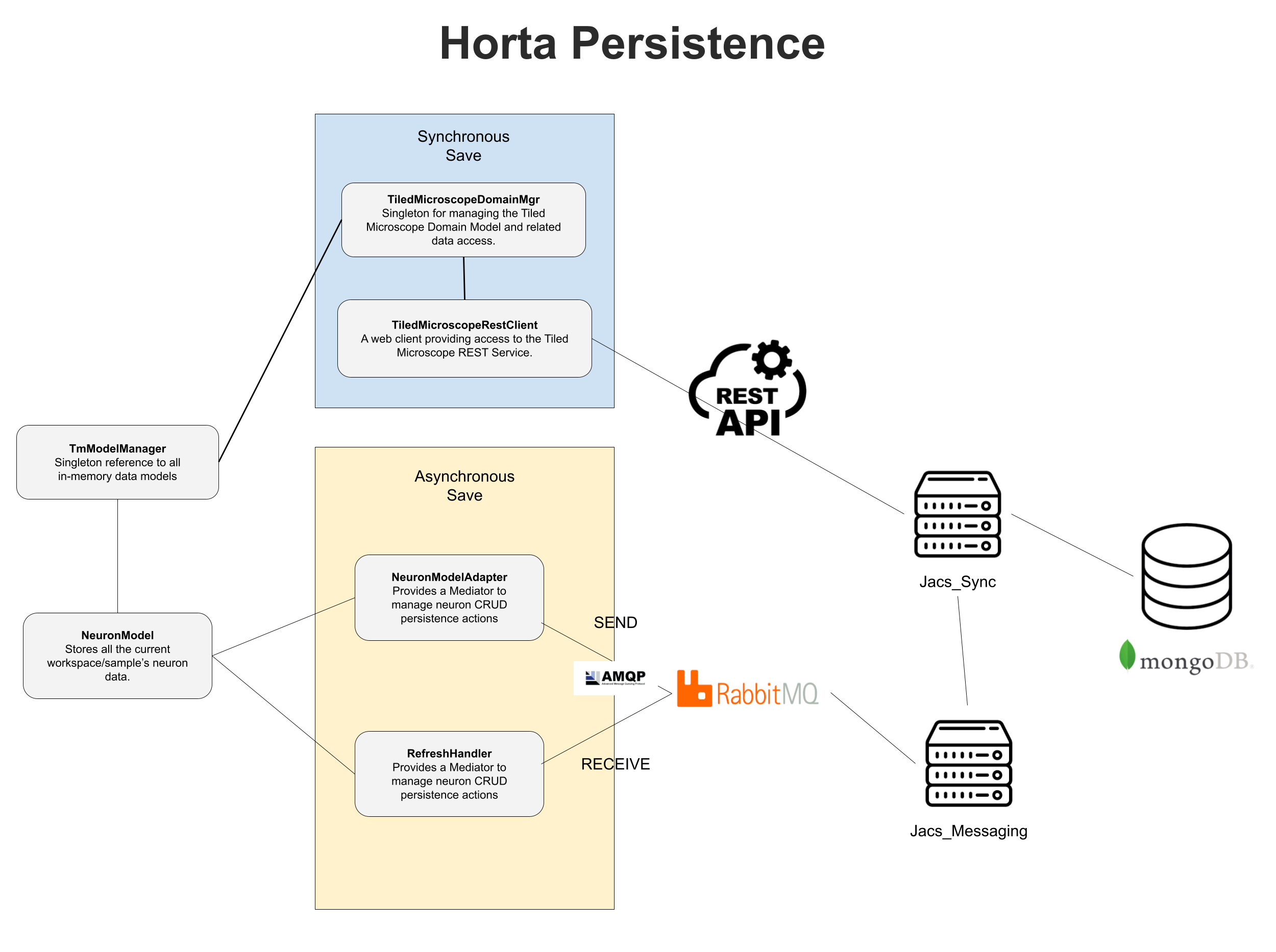
Once the workspace is initialized and the annotator makes a change to a neuron, the entire neuron is serialized into an AMQP message and sent through the NeuronModelAdapter using RabbitMQ. When a client first starts up, it creates a temperorary queue that both publishes to a RabbitMQ topic exchange (ModelUpdates). Another service, jacs-messaging, listens to this exchange using the UpdateProcessor queue, and consumes messages of the exchange. It determines how to process these messages and if it requires persisting the neuron to the db, connects over the REST API to the jacs-sync service to perform the operation.
Once the operation is complete, an acknowledgement/update message is posted on the RabbitMQ fanout exchange, ModelRefresh. If there are any errors, they get posted on the ModelError exchange. All the clients are subscribed the ModelRefresh exchange, so they get notifications on any neuron changes. These are processed as multi-threaded callbacks in RefreshHandler, which filters based off the current workspace and fires update events if the message is relevant.
Feedback
Was this page helpful?
Glad to hear it! Please tell us how we can improve.
Sorry to hear that. Please tell us how we can improve.